
我們在前三章的介紹中,深入地了解前端的監控以及 Web Vitals 的相關知識。在前端開發中,許多開發者已經熟悉了各種監控工具,這些工具可以幫助我們了解應用的健康狀況,例如網頁的載入速度、API 請求的成功率、錯誤日誌的收集等等。但隨著應用的複雜性增加,單靠監控已經不足以應對所有問題,我們還需要更深入的觀察能力來應對那些預料不到的問題。這就是為什麼我們需要在前端引入可觀測性的概念,但我相信對於前端而言,了解監控已經讓腦袋負載過重了,再聽到可觀測性或是 OpenTelemetry 這些名詞,已經頭昏眼花。所以本章節我們將會以淺顯易懂的方式介紹可觀測性的概念,以及如何透過 OpenTelemetry 來實現前端的可觀測性。
可觀測性(Observability)可以讓我們從外部了解一個系統,能夠在不深入瞭解其內部運作的情況下對系統提出問題。
這是 OpenTelemetry 官方對於可觀測性的定義,白話一點:可觀測性(Observability)是指我們不需要深入理解系統內部運作,卻能夠從外部數據(如追蹤、指標、日誌等)中推導出系統行為,並進行故障排查和效能分析。相信許多時候應用程式出現問題時,都會被追問:「為什麼會發生這種情況?」,這時候就需要可觀測性來幫助我們回答這些問題。甚至,我們可以藉由可觀測性應對那些無法預見的異常情況。
對於前端來說,可觀測性不僅僅是 RUM 所提供的網頁載入時間、互動延遲等基本指標,或是觸發告警來反應系統是否達到預設的效能要求。更需要對應用的整體交互性、效能變化、使用者行為和環境的詳細數據資料等進行深入分析。可觀測性讓我們不僅能夠看到表層的數據,還能進一步追蹤到問題的根源。
假設有一個電商網站,使用者反映商品頁面載入速度變得非常慢,影響了購買體驗。但後端的 API 請求和伺服器效能都顯示正常,沒有任何明顯的異常現象。
如果前端只有傳統的監控,可能只能看到網頁載入時間、API 請求成功率等數據,而這些數據都顯示正常,無法幫助我們直接找出問題。然而,通過引入可觀測性工具,我們可以在前端收集可觀測性的三個核心要素,也是最常見的遙測數據(Telemetry):追蹤(Traces)、指標(Metrics)和日誌(Logs)。這些數據提供更深入的分析,幫助我們找出問題的根源:
Traces 是觀察一個請求或操作的整個生命周期,例如使用者點擊商品頁面到頁面完全加載的過程。尤其是在前端與後端互動時,Traces 可以讓我們了解一個請求的整個過程,包含前端發起 API 請求、後端回應、數據解析和渲染等步驟。每個請求或操作被稱為一個 trace,而每個 trace 由多個步驟組成,這些步驟被稱為 span。
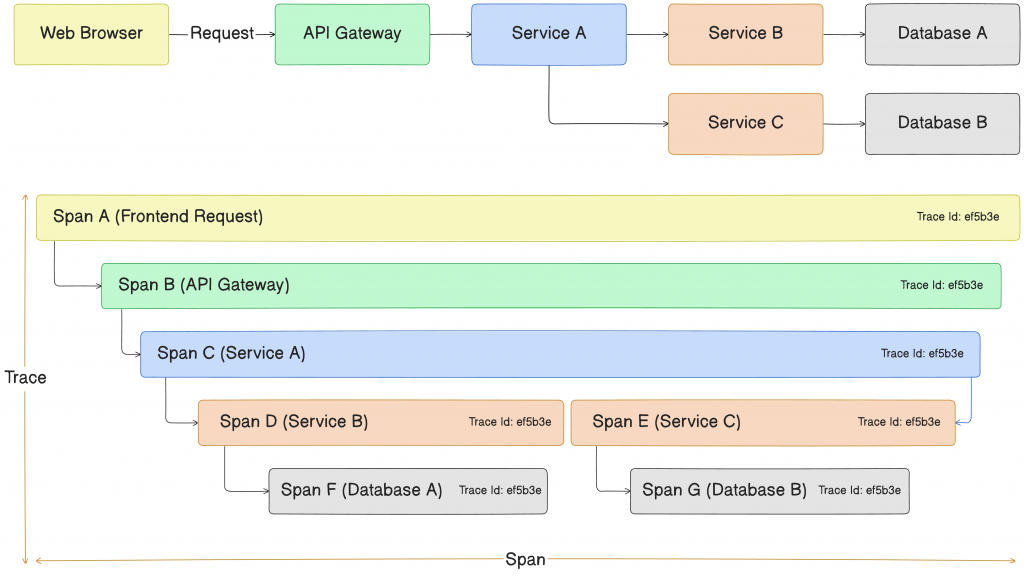
Trace 是一個請求或操作的完整記錄,從使用者在前端觸發事件開始,直到後端處理完成並返回結果。每個 trace 都有一個唯一的識別碼,稱為 Trace ID,用來統一標識整個操作流程。無論是前端發起的 API 請求,還是後端的多個微服務之間的交互,這些步驟都屬於同一個 trace,幫助我們追蹤請求的每個階段。例如上圖中的所有 span 都有相同的 Trace ID:ef5b3e。
Span 是 trace 中的每個單步操作,每個 span 記錄該步驟的起始時間、持續時間及相關的 metadata(如 HTTP 狀態碼等)。通過分析 spans,我們可以找出效能瓶頸發生在哪一環節。例如,當使用者點擊按鈕發起 API 請求時,這個 trace 可能包含以下幾個 spans:
每個 Span 都有一個唯一的 Span ID,用來標識單個操作步驟。這幫助開發者理解和分析操作流程中的每個步驟,從而精準定位問題並優化效能。
Parent 是用來表示 span 之間的層級關係的概念。每個 span 可能有一個父 span(Parent Span),表示這個步驟是在另一個更大的操作步驟中發生的。例如上圖中,當前端發起一個 API 請求時,這個請求的處理可能會分解成多個步驟(如 Service B、Service C),這些步驟就會作為更大服務 (Service A) 的子操作。這些子操作會有各自的 Span ID,並且會關聯一個 Parent Span ID,即代表它們是屬於某個更大的操作 (Service A) 的一部分。這種層級關係有助於我們理解複雜操作的結構和流程。
Metric 是在系統運行時所捕捉的測量,主要用來衡量系統或應用的狀態。每次進行測量時,稱為一次 metric event,它包含測量值、發生時間以及相關的 metadata。
應用和請求的指標是衡量系統可用性和效能的重要依據。自訂指標可以深入了解可用性對使用者體驗或業務的影響。這些數據不僅能用來發出異常警報,還可以在需求高峰時自動觸發擴展部署。
Logs 是帶有時間戳記的文字紀錄,可以是結構化(建議)或非結構化的,並且可以包含額外的 metadata。Logs 不只記錄系統中的特定事件,還能提供問題發生時的詳細背景,協助開發者診斷問題,並了解系統在某一時間點的狀態。另外,Logs 可以記錄系統運行狀況、API 請求錯誤、使用者行為等資訊,這些對於追蹤和解決問題非常重要。
而 Logs 是所有可觀測性的要素中,存在歷史最悠久的,因此大部分程式語言都內建了 Logs 功能,或有廣泛使用的記錄庫,讓開發者能夠有效收集和管理這些重要的系統資訊。
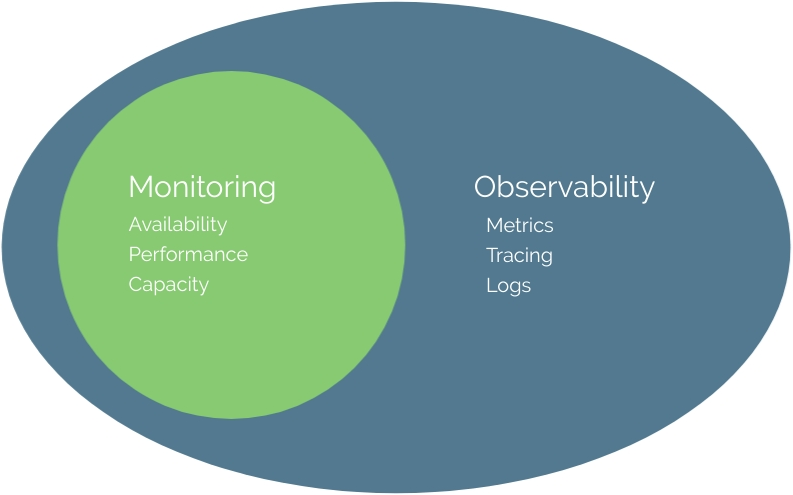
監控是系統的即時健康檢查,而可觀測性則是應對未知挑戰的問題診斷工具。
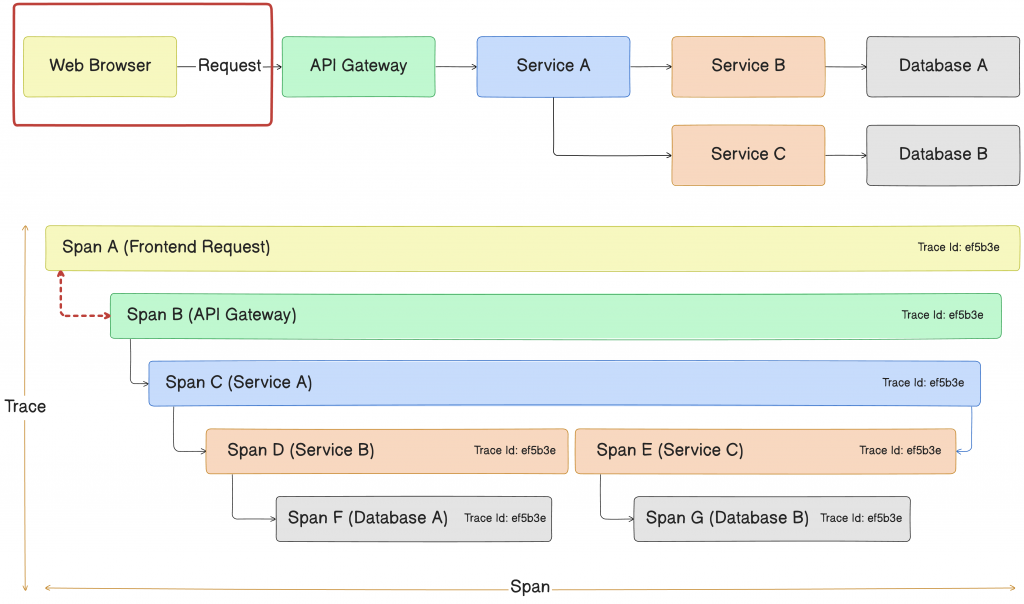
許多人在談論分散式系統的追蹤與可觀測性時,往往將後端的 API Gateway 作為追蹤的起點。然而,隨著現代前端應用的日益複雜,僅依賴後端的可觀測性已不足以全面掌握應用的效能狀況。前端的效能與穩定性對使用者體驗有直接的影響,無論是網頁載入時間、互動延遲還是錯誤處理等方面,都是評估的關鍵。
尤其在現今強調端到端(End-to-End)效能追蹤的思維下,前端這部分尚未納入的環節,需要被整合進整體可觀測性的體系中,將這串鏈條連接起來,才能讓整個追蹤流程更加完整與精準。
在這個前端可觀測性的時代,我們需要解決以下問題:
總結來說,前端可觀測性不僅能讓我們深入了解應用在真實世界中的表現,還能幫助我們更快速地發現和解決問題,從而提升整體使用者體驗。在這個日益注重效能和穩定性的時代,前端可觀測性勢必會有越來越重要的地位。

在這篇文章中,時不時會提到 OpenTelemetry,那麼,OpenTelemetry 是什麼?他與可觀測性有什麼關係?以下讓我們一起認識這個讓可觀測性變得更有秩序及依據的聖經。
OpenTelemetry 是一個開源的可觀測性框架,用來生成、收集、管理和匯出遙測數據(如追蹤、指標和日誌)。它是在 2019 年由 OpenTracing 和 OpenCensus 合併而來。這兩個專案最初是為了解決相同的問題:缺乏統一的標準來進行遙測數據的生成和傳輸。但這兩個專案各自無法完全解決問題,於是他們合併成為 OpenTelemetry,並結合雙方的優勢,解決遙測數據標準化的問題,並為開發者提供更完整的解決方案。
對前端工程師來說,OpenTelemetry 提供了標準化的方式來收集應用程式效能數據,例如追蹤使用者操作、頁面效能、API 請求等,從而幫助分析和高效解決效能問題。
隨著應用程式架構變得日益複雜,前端工程師不僅要監控客戶端效能,還要確保與後端系統的順暢交互。OpenTelemetry 通過提供標準化的 API 和靈活的遙測數據處理方式,幫助工程師實現跨系統的觀測性,並且不受限於特定供應商。
OpenTelemetry Browser 是 OpenTelemetry 的 JavaScript SDK,專門用來為 Web 應用進行遙測數據的儀器化(instrumentation),尤其是透過瀏覽器來追蹤應用程式的效能數據和使用者行為。而以下是 OpenTelemetry Browser 的特點:
由於本系列文中是以 Grafana Faro 作為最後的可觀測平台,因此可以初步了解 OpenTelemetry 執行所需要的工具和初始化,更細節的內容則交由後續的 Grafana Faro 文章中進行介紹:
安裝 OpenTelemetry SDK
npm install @opentelemetry/sdk-trace-web @opentelemetry/instrumentation-document-load @opentelemetry/context-zone
初始化 SDK
添加自定義追蹤
匯出遙測數據
OpenTelemetry Browser 透過標準的 W3C TraceContext 規範來處理追蹤數據的傳遞,這樣可以確保跨服務和平台的數據兼容性。W3C TraceContext 定義了 Trace ID 和 Span ID 的格式,這些都是遙測數據中的關鍵部分,通過這些標準格式,開發者可以將前端遙測數據與後端服務鏈接起來。
具體的 Span 呈現格式可以參考以下,包含了重要的唯一識別標籤,如 traceId 和 spanId,以及時間戳記、持續時間以了解關於這個操作是何時發生以及持續多長時間,還有 attributes 和 events 等其他資訊來描述這個操作的 HTTP 回應長度等詳細資訊和請求加載過程的關鍵時間點(如 fetchStart、domainLookupStart 等):
{
"traceId": "ab42124a3c573678d4d8b21ba52df3bf",
"parentId": "cfb565047957cb0d",
"name": "documentFetch",
"id": "5123fc802ffb5255",
"kind": 0,
"timestamp": 1606814247811266,
"duration": 9390,
"attributes": {
"component": "document-load",
"http.response_content_length": 905
},
"status": {
"code": 0
},
"events": [
{
"name": "fetchStart",
"time": [1606814247, 811266158]
},
{
"name": "domainLookupStart",
"time": [1606814247, 811266158]
},
{
"name": "domainLookupEnd",
"time": [1606814247, 811266158]
},
{
"name": "connectStart",
"time": [1606814247, 811266158]
},
{
"name": "connectEnd",
"time": [1606814247, 811266158]
},
{
"name": "requestStart",
"time": [1606814247, 819101158]
},
{
"name": "responseStart",
"time": [1606814247, 819791158]
},
{
"name": "responseEnd",
"time": [1606814247, 820656158]
}
]
}
筆者語錄
在現代前端開發中,單靠監控已經無法應對日益複雜的應用架構和使用者需求。通過引入可觀測性,能夠更深入地理解應用的內部運作,解決未知的問題。而 OpenTelemetry 作為一個強大且開源的可觀測性框架,為前端開發者提供了完善的工具,讓我們能夠透過追蹤、指標和日誌的協同作用,實現更高效的故障排查和效能優化。
https://www.facebook.com/will.fans/videos/463462881975591
https://opentelemetry.io/docs/languages/js/getting-started/browser/
https://ithelp.ithome.com.tw/articles/10341509

